Первые шаги с Jekyll на GitHub Pages
В процессе работы мне часто приходится ресерчить, искать ответы на какие-то вопросы, собирать вместе информацию из разных источников, изучать что-то новое. Из полученных таким образом знаний составлялись заметки, чтобы потом к ним можно было вернуться. В какой-то момент я понял что хочу иметь не просто записную книжку, а блог, в котором я мог бы тренироваться в оформлении своих заметок и мыслей в статьи.
Я мог бы использовать готовые платформы для ведения блогов, такие как Medium или Habr, но мне бы хотелось чтобы это был мой собственный блог, а не страница на чужом ресурсе.
Я мог бы написать сайт с нуля, или собрать его используя готовые платформы, например WordPress или Ghost, и захостить это все на арендованном сервере.

Но какие есть еще варианты? Я видел множество сайтов на домене *.github.io. Я выяснил что это такое, создал блог на GitHub Pages и решил написать о том что узнал в процессе.
GitHub Pages
GitHub Pages - это хостинг статических сайтов прямо из репозиториев GitHub.
Думаю что любой читающий эту статью не по наслышке знает что такое GitHub. Он уже давно стал не просто хранилищем кода и местом для публикации open-source проектов а так же работы над ними, но и целой соцсетью для людей так или иначе связанных с программированием.
В какой-то момент GitHub предоставил возможность хостить статические сайты прямо на платформе. И эта возможность идет вместе с репозиториями которые он предоставляет, бесплатно. Получившиеся сайты размещаются на доменах *.github.io, либо, при наличии, можно использовать свой собственный.
Этому нашлось множество применений, например:
- Создание демо к проекту, хранящемуся в репозитории
- Создание online-документации к проекту, хранящемуся в репозитории
- Ну а если ваш проект сам по себе является статическим сайтом то вы можете сразу захостить его прямо на GitHub
GitHub Pages часто используют для создания личных страниц, сайтов-портфолио и блогов.
Конечно же тут есть и ограничения. Например нужно учитывать что правилами запрещено использование GitHub Pages для коммерческих сайтов.
Давайте разберемся что такое статический сайт, и какие ограничения он накладывает. Статический сайт - это просто набор статических веб-страниц (html/css/js). Для программиста это означает отсутствие базы данных, отсутствие бэкенда и серверного рантайма (если вы, конечно, не подключите ваш сайт к какому-то стороннему API, размещенному где-то еще). Документация GitHub Pages дает похожее определение сайтам, которые могут быть размещены на платформе, и прямо говорит о том что работа с языками программирования, работающими на сервере, не поддерживается. Резюмируя, можно описать это так: GitHub Pages просто предоставляет веб-сервер для файлов которые хранятся у вас в репозитории.
Но это еще не все! Помимо этого GitHub Pages предоставляет возможность использования генератора статических сайтов Jekyll. Он может существенно облегчить задачу и заменить бэкенд в ряде случаев. Разберем это подробнее.
Jekyll
Jekyll - это генератор статических сайтов ориентированный на создание блогов. Задача генератора - это сгенерировать набор статических веб-страниц из какого-то набора данных. В нашем случае набором данных выступают файлы в репозитории. Например, с его помощью я могу хранить статьи в текстовом формате - а Jekyll сам сгенерирует мне по веб-странице на каждую статью.
Пройдемся по основным моментам Jekyll:
- Настройки. Все настройки Jekyll хранятся в файле
_config.yml. Его нужно создать если его еще нет или отредактировать. Если вы не хотите использовать Jekyll в GitHub Pages то в репозитории нужно создать файл с названием.nojekyll - Страницы могут быть описаны в формате markdown или HTML. Мне нравится markdown, так что для меня это плюс. Страницы должны содержать шапку с описанием технической информации, такой как название, категория, используемый шаблон и прочее. Вы можете добавлять в шапку и собственные поля. Само тело страницы является шаблоном, который Jekyll может наполнить указанными вами данными. В качестве синтаксиса шаблонов используется Liquid.
- Коллекции - это способ объединить файлы и работать с ними как с массивом.
- Статьи - это готовая коллекция, предназначенная для хранения записей в блоге. Страница становится статьей если она лежит в папке
_posts, а файл с ней назван по формату{год}-{месяц}-{день}-{заголовок}.{формат}. Черновики должны лежать в папке_drafts, и будут отображаться только если Jekyll будет запущен с параметром--drafts. - Поддержка Sass/SCSS. Если вы хотите писать стили используя Sass или SCSS, то Jekyll сам скомпилирует их в CSS.
- Темы. Если вы не хотите заниматься внешним видом вашего сайта, то существует множество готовых тем. Более того, темы включают в себя практически полную настройку Jekyll. То есть, если вы используете тему, то достаточно будет только заполнить кое-какие настройки и добавлять новые статьи в
_posts. Минимальный порог вхождения. - Плагины. Для Jekyll написано множество плагинов, которые существенно расширяют его возможности. К сожалению, есть ограничения для Jekyll, работающего в GitHub Pages - могут быть использованы только разрешенные плагины.
- Подсветка кода - не мало важная функция для программиста.
Создание блога на GitHub Pages
В официальной документации подробно рассказано как создать свой сайт с помощью GitHub Pages и Jekyll. Я делал все по инструкции и получил работающий сайт. Не буду заострять на этом внимание т.к. это действительно очень просто, и это большой плюс GitHub Pages.
Вместо этого я бы хотел пройтись по возможностям, которые я пытался реализовать, и проблемам, с которыми столкнулся.
Итак, Jekyll - это генератор статических сайтов. Значит сайты, построенные с его помощью, ограничены в использовании динамического контента. А такие вещи как, например, поиск или фильтрация статей по тэгам обычно требуют чтобы контент загружался динамически. Значит я не смогу этого сделать? Или есть какие-то обходные пути? Рассмотрим по пунктам.
Поиск
Не существует способа сделать корректный поиск, загружающий только отфильтрованные статьи с сервера.
Для такого поиска требуется запрос типа GET /search/{searchText} где searchText - текст, по которому мы ищем статьи. Сделать searchText переменной невозможно т.к. это статический сайт, и сгенерировать по странице на каждый searchText тоже невозможно т.к. количество страниц будет почти бесконечным.
Так какие есть варианты?
Фильтрация на клиенте
Можно сделать страницу содержащую все статьи, и фильтровать эти статьи используя JavaScript в браузере после загрузки. Например:
Нужно создать скрипт search.js, страницу search.html и подключить скрипт к ней:
1
<script src="{{ '/assets/js/search.js' | relative_url }}"></script>
На странице нужно разместить строку поиска:
1
<input type="text" id="search-input"/>
В скрипте указать что при изменении строки поиска должна запускаться функция поиска:
1
2
3
4
5
6
7
8
9
10
const input = document.getElementById('search-input');
input.addEventListener('change', search);
function search() {
// do something
}
// Показать все статьи при первой загрузке
search();
Тело функции будет зависеть от способа реализации, я опишу два варианта.
Вариант 1: статьи в HTML
В search.html создаем блок, содержащий результаты поиска и показываем в нем все статьи через цикл, например так:
1
2
3
4
5
6
7
<div id="search-results">
{% for post in site.posts %}
<div id="{{ post.id }}">
<!-- article content -->
</div>
{% endfor %}
</div>
Фунция поиска в этом случае должна скрывать те статьи, текст которых не сожержит строки поиска. Пишем реализацию:
1
2
3
4
5
6
7
8
9
10
11
12
13
function search() {
query = input.value;
const resultsNode = document.getElementById('search-results');
for (const articleNode of resultsNode.children) {
if (!articleNode.innerHTML.includes(query)) {
articleNode.hidden = true;
} else {
articleNode.hidden = false;
}
}
}
Вариант 2: статьи в JS
В search.html создаем пустой блок для результатов поиска.
1
<div id="search-results"></div>
Добавляем в search.js шапку для того чтобы Jekyll начал его обрабатывать, переводим все статьи в формат JSON и помещаем их в переменную JS:
1
2
3
4
---
# This is necessary for the file to be processed by Jekyll
---
const posts = {{ site.posts | jsonify }};
Фунция поиска в этом случае должна добавлять к блоку результатов поиска те статьи, которые содежат строку поиска. Такой подход, кстати, можно применять и для других фильтров. Пишем реализацию:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
function search() {
query = input.value;
const resultsNode = document.getElementById('search-results');
resultsNode.innerHTML = '';
for (const post of posts) {
if (post.content.includes(query)) {
const articleNode = document.createElement("article");
articleNode.innerHTML = '<div><!-- article content --></div>';
resultsNode.appendChild(articleNode);
}
}
}
Точно такой же подход для поиска по статьям используется в npm-библиотеке simple-jekyll-search.
Но в целом - это плохое решение т.к. пользователь будет всегда загружать с сервера все статьи, независимо от того, сколько из них ему нужно показать. При большом количестве статей это может стать проблемой.
Google CSE
В качестве альтернативы можно добавить Google CSE на сайт. Он будет открывать Google с поиском по вашему сайту. Документацию можно найти по ссылке.

Поразмыслив над всеми вариантами, я решил не делать поиск на этом этапе.
Тэги
Jekyll имеет встроенную поддержку тэгов - они являются частью перечисляемых в шапке страницы параметров. Но если вам нужна страница которая открывается по клику на тэге и показывает все статьи с этим тэгом - в Jekyll такого нет. По большому счету вам нужно что-то вроде эндпоинта /tags/{tag} который бы возвращал список статей отфильтрованных по {tag} - это динамический контент. Но в Jekyll не существует параметров запросов, не существует динамических путей - только статические страницы.
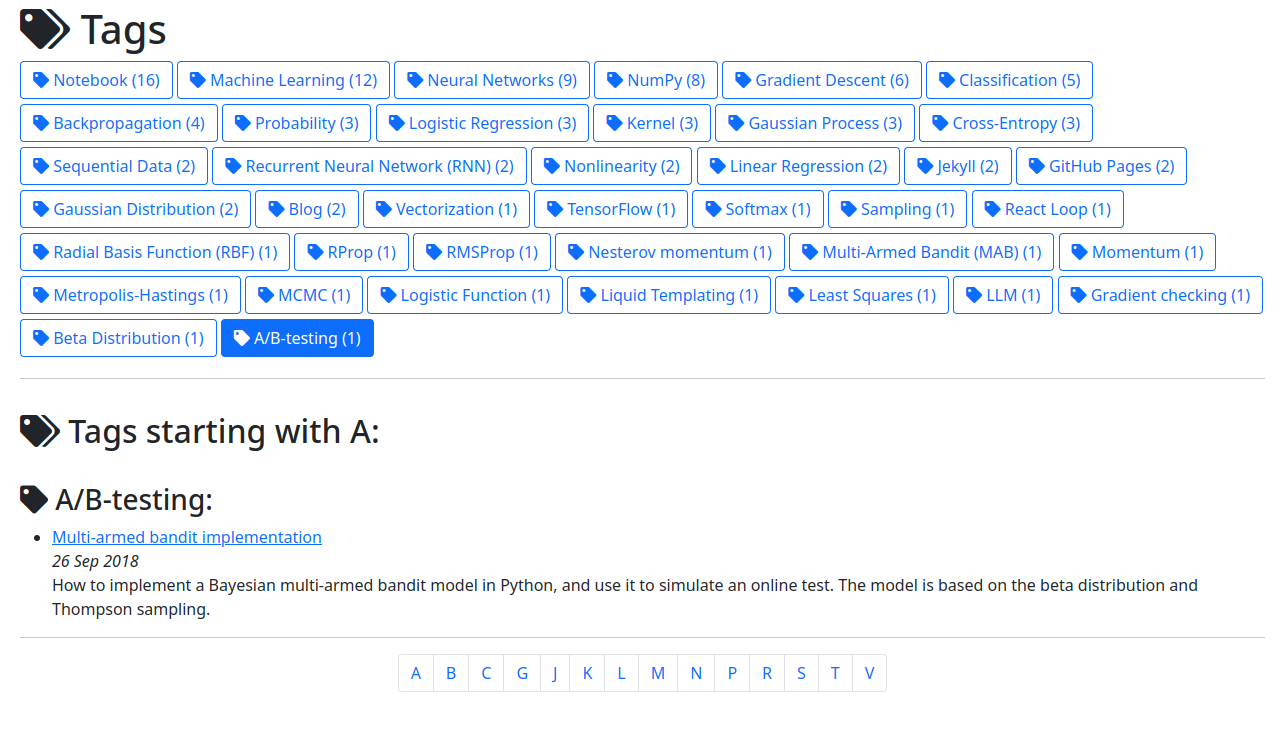 Скриншот блога peterroelants.github.io
Скриншот блога peterroelants.github.io
Я вижу всего 2 способа как сделать страницу с статьями, отфильтрованными по тэгу:
Единая страница для тэгов
Это решение очень похоже на то, что я предлагал для поиска. Нужно создать страницу tags.html и наполнить ее всеми существующими статьями с разбивкой по тэгам:
1
2
3
4
5
6
7
8
9
10
<div id="tags-contaiter">
{% assign tags = site.tags | sort %}
{% for tag in tags %}
<div id="{{ tag[0] }}">
{% for post in site.tags[tag[0]] %}
<!-- article content -->
{% endfor %}
</div>
{% endfor %}
</div>
Теперь у нас есть несколько вариантов как “подсветить” выбранный тэг (я буду указывать выбранный тэг как ${tag}).
Вариант 1: использование хэша в адресе
Самый простой вариант. Делаем ссылки на тэги сдедующего вида: /tags#${tag}. Страница tags.html по таким ссылкам будет открываться сразу со скроллом на нужном тэге, т.к. мы прописали его в аттрибуте id. Прочие тэги можно даже не скрывать.
Пример такой реализации страницы с тэгами можно посмотреть в блоге peterroelants.github.io. Помимо этого, в его блоге есть статья в которой описано как это устроено.
Вариант 2: статьи и фильтрация в JS
Сделать все аналогично поиску с хранением статей в JS, описанному выше. Кладем JSON со статьями в JS-переменную, фильтруем их по тэгу и отображаем. Единственное отличие - нам нужно откуда-то взять тэг, по которому мы будем фильтровать. Для этого я предлагаю использовать параметры запроса: делаем ссылки на тэги следующего вида /tags?tag=${tag}, после чего получаем его в JS следующим образом:
1
2
const urlParams = new URLSearchParams(window.location.search);
const myParam = urlParams.get('tag');
Либо используем тот же хэш /tags#${tag}:
1
const tag = window.location.hash.substr(1);
Так или иначе будет известен тэг, с которым нужно будет сравнить список тэгов каждой статьи, и показать те у которых они совпадают.
По странице на тэг
Более правильное решение, заключающееся в том что каждый тэг является отдельной страницей.
Для начала нужно будет создать общий шаблон tag_posts.html, который будет отображать статьи, отфильтрованные по тэгу. Сделать это можно с помощью цикла, например, так:
1
2
3
{% for post in site.tags[page.tag] %}
<!-- article content -->
{% endfor %}
Остается только записать текущий тэг в page.tag. Для этого в папке tags потребуется создать по странице на каждый тэг. Название страницы должно совпадать с названием тэга, чтобы при переходе на /tags/{tag} у нас открывалась именно эта страница. Сами страницы будут пустыми ведь в качестве контента мы используем шаблон созданный выше, и заполнить нужно будет только шапку:
1
2
3
4
---
layout: tag_posts
tag: {tag}
---
К счастью, описанные действия уже автоматизировали, существует Github Action который генерирует такие страницы для тэгов. Инструкции и более детальный анализ проблемы можно найти в блоге автора этого Action’а.
Решение с единой страницей для тэгов, на мой взгляд:
- простое в реализации
- хуже для SEO
- будет плохо работать на большом количестве статей (пользователь будет вынужден загрузить все статьи чтобы фильтровать их)
Решение с страницей на каждый тэг:
- сложное (при добавлении нового тэга нужно каждый раз создавать новую страницу, страниц может быть очень много)
- лучше для SEO
- будет работать лучше при большом количестве статей (пользователь будет загружать только отфильтрованные статьи)
На данный момент я остановился на втором решении.
Пагинация
Я не знаю сколько статей будет в моем блоге через какое-то время. 1? 10? 100? Неизвестное количество. Я считаю что “если количество элементов может превышать 100 то имеет смысл использовать пагинацию”.
 Пагинатор
Пагинатор
Пагинация - это, определенно, динамический контент. Но в Jekyll это возможно благодаря плагину jekyll-paginate, который позволяет настроить пагинацию для статей.
Чтобы использовать плагин нужно отредактировать файл в файле _config.yml. В нем нужно указать его название в блоке plugins, а так же задать настройки:
1
2
3
4
5
paginate_path: /posts/:num/ # путь к страницам с пагинацией, :num - это номер страницы
paginate: 10 # количество элементов на странице
plugins:
- jekyll-paginate
Стоит отметить что jekyll-paginate не совместим со способами поиска и фильтрации статей, которые я описывал выше.
Если я использую пагинацию для отображения статей, то и в поиске, и при отображении статей “по тэгу” следует отображать только первые N элементов отфильтрованных результатов. Но это невозможно т.к. jekyll-paginate просто берет все статьи и генерирует набор страниц по N статей на каждой.
Плагин прост в установке и работает хорошо. Но он стал причиной из-за которой я не стал делать поиск.
Когда пагинация есть только на главной странице, а на остальных страницах перечисляющих статьи её нет - это как будто делает ее бессмысленной.
i18n
i18n - это аббревиатура, используемая для обозначения интернализации и локализации.
Я бы хотел писать статьи на двух языках. Следовательно и элементы интерфейса всего сайта должны быть переведены на два языка. Нужно чтобы при входе на сайт считывался системный язык пользователя, и интерфейс сайта отображался на нем.
Для статического сайта самое простое решение этой задачи - это создание нескольких версий сайта (по одной для каждого языка). Например:
-
Русский
https://flametaichou.github.io/ru/blog
https://flametaichou.github.io/ru/tags
https://flametaichou.github.io/ru/tags/i18n
… -
English
https://flametaichou.github.io/en/blog
https://flametaichou.github.io/en/tags
https://flametaichou.github.io/en/tags/i18n
…
Таким образом пришлось бы делать по 2 вариации каждой страницы.
Это неудобно, особенно когда страниц много. Поэтому обычно в таких случаях поступают иначе: страницы сайта (верстка, стили, наполнение) пишутся 1 раз с использованием кодов локализации. Для каждого языка создается файл локализации, где каждому коду сопоставляется строка на этом языке. Когда пользователь запрашивает страницу все коды локализации заменяются на строки из файла с тем языком, которой запросил пользователь. Таким образом пользователь получает страницу на нужном ему языке.
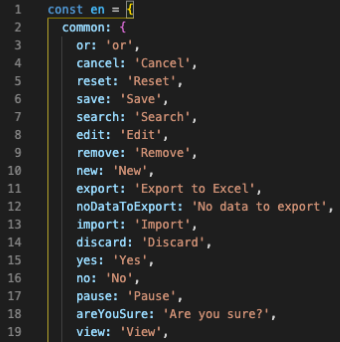 Пример файла локализации
Пример файла локализации
В Jekyll нет никакой заявленной функциональности для мультиязычности, но в интернете есть множество примеров того как ее реализуют:
- https://sylvaindurand.org/making-jekyll-multilingual/ - Making Jekyll multilingual
- https://www.usecue.com/blog/multilingual-jekyll-websites/ - Multilingual Jekyll websites
- https://meumobi.github.io/jekyll/2019/06/05/multi-languages-with-jekyll.html - Deploy a multi-language jekyll site
- https://leo3418.github.io/collections/multilingual-jekyll-site.html - Build a Multilingual Jekyll Site
- https://forestry.io/blog/creating-a-multilingual-blog-with-jekyll/ - Creating a Multilingual Blog With Jekyll
- https://www.kooslooijesteijn.net/blog/multilingual-website-with-jekyll-collections - Making a multilingual website with Jekyll collections
Решения получаются довольно разные, поэтому я начну с описания наиболее общих моментов.
Плагины
Для локализации в Jekyll существует ряд плагинов:
Они позволяют писать страницы с использованием кодов локализации. В основном принцип их работы заключается в том что вы пишете единственный шаблон страницы, а плагин на этапе сборки генерирует все ее вариации для каждого языка. Помимо этого они упрощают работу с ресурсами - можно определить какая статья или изображение должны отображаться для того или иного языка.
К сожалению, GitHub Pages не поддерживает работу с этими плагинами.
На мой взгляд GitHub Pages очень не хватает таких плагинов, реализующих автоматическую генерацию страниц. Например: тэги, пагинация, языки - все это достигается за счет автоматической генерации страниц. И если для пагинации здесь имеется готовый плагин, то для локализации нет ничего. В результате мы видим множество авторов, вынужденных “соревноваться” в способах реализовать i18n.
Если вам интересна эта тема то существует issue в репозитории GitHub Pages с просьбами добавить поддержку плагинов для локализации.
Определение языка
Для определения системного языка пользователя может быть использован JavaScript navigator API.
Google Translate
Отдельно стоит упомянуть что для статей, написанных на языке отличном от языка пользователя, можно подключить инструмент Google Translate для сайтов или воспользоваться интерфейсом Google Translate.

Собственная реализация
Прежде чем приступить к реализации нужно определиться с требованиями к конечному результату. Далее я буду описывать то, что мне требовалось, и то как я это реализовал.
Я не ставлю перед собой задачу получить по 2 варианта каждой статьи (на двух языках). На мой взгляд язык - это часть статьи. Если я переведу статью то у меня получится новая статья, а не “другая версия” старой. На мой взгляд было бы некорректно показывать на одном языке одну статью, а на другом - другую. На всех языках должны отображаться все статьи. Следовательно, мне не нужно фильтровать статьи по языку (кстати, фильтр по языку тоже не смог бы работать с jekyll-paginate).
Если же вам нужно именно отображать разные статьи для разных языков - посмотрите статьи из списка, который я привел выше. Среди них есть примеры реализации подобного.
Я задал доступные языки и язык по-умолчанию в файле настроек _config.yml так же, как это сделано в перечисленных выше плагинах.
1
2
lang: 'en'
languages: ['en', 'ru']
Они потребуются для того чтобы знать на какие языки возможен перевод, и на каком отображать страницы по-умолчанию.
В папке с данными _data я создал файлы локализации, где определил переводы на разные языки кодов локализации. Выглядит это так:
en.json
1
2
3
4
5
6
7
8
{
"home": "Home",
"posts": "Posts",
"tags": "Tags",
"bookmarks": "Bookmarks",
"about": "About",
...
}
ru.json
1
2
3
4
5
6
7
8
9
{
"home": "Главная",
"posts": "Блог",
"tags": "Тэги",
"bookmarks": "Библиотека",
"about": "О сайте",
...
}
Весь текст интерфейса (и некоторых страниц) был заменен на коды локализации. Но т.к. у меня в распоряжении нет плагинов - я не смог сгенерировать разные страницы для разных языков. Вместо этого я сделал сомнительную вещь - перевод средствами JavaScript.
Идея следующая: Jekyll отдает каждую страницу на том языке, который установлен по-умолчанию в файле _config.yml. Каждому переводимому блоку текста был присвоен аттрибут name в значении которого был указан его код локализации. После того как страница загружается в браузере JavaScript находит все такие блоки, после чего подменяет текст в них на перевод на нужном языке. Для того чтобы поместить содержимое файлов локализации в контекст скрипта был использован Liquid. Его можно использовать с любыми файлами, если добавить к ним такую же шапку какая добавляется к страницам. Реализацию скрипта можно посмотреть здесь.
Для удобства был написан компонент, который я подставляю там где мне нужен переводимый текст:
i18n.html
1
2
3
<span name="i18n.{{ include.code }}">
{{ site.data.i18n[lang][include.code] | default: include.code }}
</span>
Пример использования:
1
2
3
<a href="/posts">
{% include components/i18n.html code = 'posts' %}
</a>
Я не могу назвать это решение хорошим, ведь страница сначала загружается на одном языке, а затем переводится на другой. Скорее всего это - плохой вариант для SEO. Но я так же знаю что многие SPA без SSR делают локализацию по похожему принципу, это так же подтверждается множеством готовых i18n-библиотек для JS. Поэтому я остановился на таком решении, на данном этапе оно меня устраивает.
Возможно имеется лучшее решение и я буду рад о нем узнать.
Ссылки у заголовков
Вы можете делиться ссылками на определенный блок на сайте, если он обладает уникальным идентификатором. Идентификатор в этом случае добавляется к адресу, отделяясь символом # - эту часть так и называют “хэшем” адреса. Такая ссылка, будучи открытой, автоматически проскроллит страницу до указанного в хэше блока. Такие ссылки еще называют якорями или пермалинками.
Например, вот ссылка на этот раздел статьи.
Чаще всего такие ссылки ссылаются на заголовки (headings) на страницах. Думаю, вы не раз замечали иконки в виде звеньев цепи на заголовках статей:
 Скриншот markdownguide.org
Скриншот markdownguide.org
 Скриншот github.com/jekyll
Скриншот github.com/jekyll
 Скриншот jekyllrb.com
Скриншот jekyllrb.com
Эти иконки предназначены для того чтобы можно было быстро скопировать ссылку на конкретное место в статье.
Для того чтобы добавить такие в свой сайт на Jekyll можно воспользоваться готовыми решениями. Я не нашел готовых плагинов, реализующих это, но существует вот такая реализация на Liquid которую можно скопировать к себе и использовать.
Помимо этого существуют готовые реализации на JavaScript, которые добавляют ссылки ко всем заголовкам после загрузки страницы, например anchorjs. Такой скрипт можно подключить через CDN.
Скрипт получается очень простым, поэтому я решил не подключать чужой, и написал свой. Посмотреть его можно здесь: headers.js
Комментарии
Неотъемлимой частью любого блога являются комментарии к записям. Но, создавая сайт на Jekyll, нужно помнить что это генератор статических сайтов, а комментарии - это по определению динамический контент, подразумевающий что они где-то будут храниться, и как-то добавляться на сайт. Поэтому здесь можно было бы написать простое заключение: комментариев на статическом сайте быть не может.
Но, на самом деле, способы добавить блок с комментариями в Jekyll все же есть. Для этого потребуется подключить сторонние сервисы.
Сторонние сервисы
Disqus - веб-сервис, предоставляющий возможность импорта интернет-обсуждений и комментариев на сайт пользователя. Наверное это самое популярное решение в этой сфере. Блок с комментариями Disqus встречается на очень многих сайтах
Его можно будет так же легко подключить и на сайт, созданный с помощью Jekyll.
Инструкция на сайте Disqus говорит о том что поддержка их сервиса уже включена в Jekyll. Достаточно только включить комментарии у нужной статьи
1
2
3
---
comments: true
---
Об этом же говорят другие статьи. Но подтверждения этому в документации Jekyll я не нашел, только плагин disqus-for-jekyll которого нет в списке разрешенных на GitHub Pages. Похоже что поддержка disqus реализована только в некоторых темах, таких как minima.
Но, даже без всего этого, не составит труда подключить disqus вручную. Аналогичным образом можно подключить блок комментариев от Facebook или, например intensedebate.
GitHub Issues
Т.к. в статье идет речь о GitHub Pages в голову приходит интересная идея: а нельзя ли использовать Issues у репозитория с блогом в качестве комментариев? Кажется что все идеально совпадает - если создать issue на каждую статью то получаются готовые комментарии. Пользователю, оставляющему комментарий, не нужно логиниться в какой-то сторонний сервис. Комментарии оставляются с учетных записей GitHub - того же сервиса, на котором размещен блог. Это бы позволило видеть в комментариях профили GitHub, что на мой взгляд было бы очень удобно.
Такое решение уже есть: utteranc.es. Принцип его работы очень прост - обсуждение issue вставляется в страницу через <iframe>.
Запуск
В процессе работы над сайтом необходимо иметь возможность запускать его у себя на компьютере для проверки. Для того чтобы запускать Jekyll в связке с GitHub Pages существует готовый ruby gem.
У меня возникли проблемы с зависимостями Jekyll которые начинались с того что требовалась 2 версия ruby, а у меня была установлена 3. Конечно можно было воспользоваться RVM, но чтобы не устанавливать ничего лишнего в свою систему я решил запустить Jekyll в Docker-контейнере.
Docker Hub предложил готовый образ Jekyll для GitHub Pages. Но его запуск завершался ошибками типа
Retrying fetcher due to error (4/4): Bundler::HTTPError Could not reach host www.rubygems.org. Check your network connection and try again.
Причину которых я не смог найти.
Не сумев запустить jekyll/jekyll:pages я воспользовался образом starefossen/github-pages (Docker Hub / GitHub) который запустился без проблем.
Внешний вид
Для Jekyll существует огромное множество готовых тем. Для Jekyll, работающего на GitHub Pages этот список ограничен только поддерживаемыми темами. Для установки таких тем достаточно отредактировать настройки _config.yml, инструкция по установке конкретной темы может быть найдена в README к ней.
Если существующие темы не подходят - всегда можно создать свою, создав стили сайта с нуля или отредактировав одну из существующих тем.
Вот и я решил делать свою потому что мне это интересно. Поигрался с цветами и проиграл:
Финальный вид:
Заключение
Работая над этим сайтом я как будто вернулся на 15 лет назад, когда интернет еще состоял из набора статических html-страниц. Но самым большим ограничением здесь является отсутствие базы данных и возможности реализовать какую-либо серверную логику.
Создавая сайт на GitHub Pages с Jekyll нужно понимать для чего он предназначен. Он может быть хорош для простых вещей - лендингов, претензаций, документации. Можно создать на нем и простейший блог: если требования минимальны, и нужно просто где-то публиковать записи и ничего больше - это прекрасный вариант.
Но нужно понимать что он будет уступать по возможностям многим другим платформам и уж тем более самописанному сайту. Выводы:
- Я не смог реализовать поиск по статьям
- Мне нужно генерировать страницы тэгов при каждой сборке сайта
- Пагинация работает на единственной странице и не может работать с поиском, с тэгами или с другими фильтрами
- Локализация страниц происходит в браузере посетителя сайта, а не на сервере
- Я не подключил комментарии
Да, действительно, при желании все перечисленное можно реализовать, но способы реализации трудно назвать хорошими. Это постоянный поиск нестандартных решений, работа с ограничениями. Это полезный опыт для того чтобы попробовать что-то непривычное в плане технологий, узнать что-то новое, повторить основы веб-разработки, ведь, как известно, все новое - это хорошо забытое старое. Но, безусловно, это не самый простой путь от задумки к готовому решению.
Помимо всего прочего в процессе работы над этим сайтом, над статьей, у меня появилось еще несколько идей которые я не успел опробовать:
- Попробовать запаковать SPA в GitHub Pages - для этого его нужно собрать, закоммитить скомпилированную папку dist, указать ее в GitHub Pages
- Наполняя JSON с помощью Liquid сделать подобие REST API, которое потом использовать в SPA
- В GitHub Pages возможно использование и других генераторов статических сайтов (например Hugo) помимо Jekyll, но их использование требует гораздо больше усилий. Вот инструкция. Их использование может открыть большие возможности, чем есть в Jekyll.
- Попробовать использовать Google Docs в качестве бекенда
Помимо этого я планирую работать дальше над внешним видом сайта, а так же дописать продолжения этой статьи про подсветку синтаксиса и комментарии.
Благодарности
Хочу привести список блогов, которые я использовал как примеры, и выразить благодарность их авторам
- https://jun711.github.io/
- https://mcpride.github.io/en/
- https://leo3418.github.io/
- https://meumobi.github.io/
- https://peterroelants.github.io/
- https://qian256.github.io
- https://chadbaldwin.github.io
- https://hendrixjoseph.github.io
- https://lipanski.com/
- https://sylvaindurand.org/
- https://www.usecue.com/